Food recalls happen every day. A contaminated batch of cheese. Undeclared allergens in packaged snacks. Metal fragments found in baby food. Behind each recall notice lies a potential public health risk—and a race against time.
But what if we could automatically detect and categorize food hazards from thousands of public reports, faster and more accurately than ever before?
At SemEval-2025 Task 9 (The Food Hazard Detection Challenge), our team BitsAndBites proposed a novel AI approach that significantly improves how food recall reports are classified. As part of the broader vision of the EFRA (Extreme Food Risk Analytics) project, this work contributes to building more intelligent systems for monitoring and analyzing food risks at scale.
The Challenge: Food Hazard Detection Is Not Just Classification
Food recall reports are publicly available from government agencies across the world. They are authoritative—but messy:
- Written in different formats
- Spanning nearly three decades
- Containing thousands of possible product and hazard labels
- Exhibiting strong dependencies between products and hazards
Food recall reports are publicly available from government agencies across the world. They are authoritative—but messy:
- Subtask 1 (ST1): Classify reports into broad product categories (22 labels) and hazard categories (10 labels).
- Subtask 2 (ST2): Identify fine-grained products (1,142 labels) and hazards (128 labels).
Traditional single-head classifiers struggle because products and hazards are related but distinct tasks.
Our Solution: Sequential Multi-Head Classification
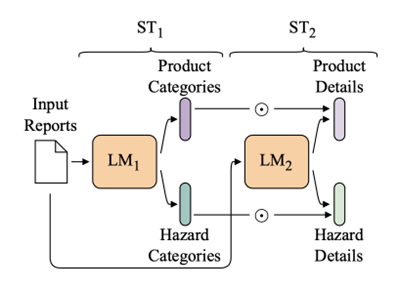
1. Multi-Head Architecture
We split the classification layer into two heads: one for products and one for hazards. Both share the same RoBERTa-large backbone but specialize in their prediction task. For each subtask (ST1 and ST2), we train one classification model with two classification heads: one for classifying the product labels, and one for classifying the food hazard. Then, we constrain the probabilities of the ST2 detailed labels based on the probabilities of the ST1generic categories.
Impact:
- +30% absolute F1 improvement for product classification
- +46% absolute F1 improvement for hazard classification
2. Sequential Classification
We leverage the hierarchical structure of labels by first predicting high-level categories (ST1), then constraining fine-grained predictions (ST2) based on those probabilities. This ensures hierarchical consistency and improves robustness.
3. LLM-Based Report Normalization
We used Meta-Llama-3.1-8B-Instruct in zero-shot mode to extract structured summaries from each report in a uniform format:
- PRODUCT: <food product and category>
- HAZARD: <motivation and category>
This reduced variability across reports and slightly improved classification stability.
Results
- F1 = 0.80 for product classification (ST1)
- F1 = 0.47 for hazard classification (ST2)
- 6th place in ST1 and 13th place in ST2 on the public leaderboard
Why This Matters for EFRA
Within the EFRA project, this work supports early detection of food safety risks, large-scale monitoring of food recall reports, improved traceability and structured analytics, and scalable AI for extreme food risk scenarios.
By combining multi-head learning, hierarchical reasoning, and LLM-driven normalization, we move closer to intelligent systems that better understand real-world food hazard data.
This research was carried out within the EFRA (Extreme Food Risk Analytics) project, funded by the European Union’s Horizon Europe programme (Grant Agreement No. 101093026).

