Our team recently faced the challenge of orchestrating a distributed system on Google Cloud, with high demands for scalability, resilience, and portability. We chose to build everything on Google Kubernetes Engine (GKE), managing infrastructure with Terraform and deploying applications with Helm. Here’s a technical breakdown of why and how we did it.
EFRA Platform Overview
The EFRA platform aims to be a comprehensive solution, dedicated to food risk safety analysis. It seeks to enable multi-party collaboration, accommodate scalability, reduce energy consumption, optimise resource allocation, and support advanced AI learning techniques to enhance food safety efforts on a global scale. EFRA platform is based on the following core components:
EFRA Data Hub: A cloud native platform for storing, accessing, filtering and managing all data collected and produced within the project (e.g. the data sources registry instructing the crawlers, the documents collected by the crawlers, the annotations/predictions generated by AI models, the knowledge graphs semantically structuring domain entities and concepts, the AI models used in the Powerhouse).
EFRA Analytics Powerhouse: The main goal of the EFRA Analytics Powerhouse is to distil usable signals from the datasets stored in the EFRA Data Hub by means of AI models that extract semantic features from the raw documents (e.g. food safety hazards, products/producers, locations, food categories) and ultimately predict food safety risks. Each AI module is tailored to a specific type of data and optimised to leverage the annotations and links (if available) to seek specific food safety signals.
EFRA Data & Analytics Marketplace: A front-facing user-friendly web app that allows interested users to discover, purchase/use, and contribute with raw data, AI models, and analytics modules, thus creating an economy where data holders and data consumers can engage and trade.
EFRA core components were designed and implemented as cloud native applications, following the microservices paradigm. For the deployment, scaling and orchestration of EFRA microservices the Kubernetes platform has been adopted.
What is Kubernetes?
Kubernetes is an open-source platform for container orchestration. It automates the deployment, scaling, and management of containerized applications — essentially acting as the operating system for modern cloud-native infrastructure.
Why Kubernetes over traditional VM-based infrastructure?
- Auto-scaling: Kubernetes automatically scales pods and nodes based on workload.
- Declarative configuration: everything is defined in YAML, making it easy to version and audit.
- High availability: workloads are distributed across nodes to ensure fault tolerance.
- Portability: containerized apps can run anywhere (on-prem on any cloud) without vendor lock-in.
What makes Google Kubernetes Engine (GKE) special?
GKE is Google Cloud’s managed Kubernetes service. It offers:
- Automatic upgrades and patching of the control plane.
- Native integration with Google services like IAM, Cloud Logging, and Monitoring.
- Advanced autoscaling at both pod and node levels.
GKE is fully compatible with any Kubernetes cluster, whether self-hosted or managed by other providers like AWS (EKS) or Azure (AKS). This ensures that your configurations remain portable across environments.
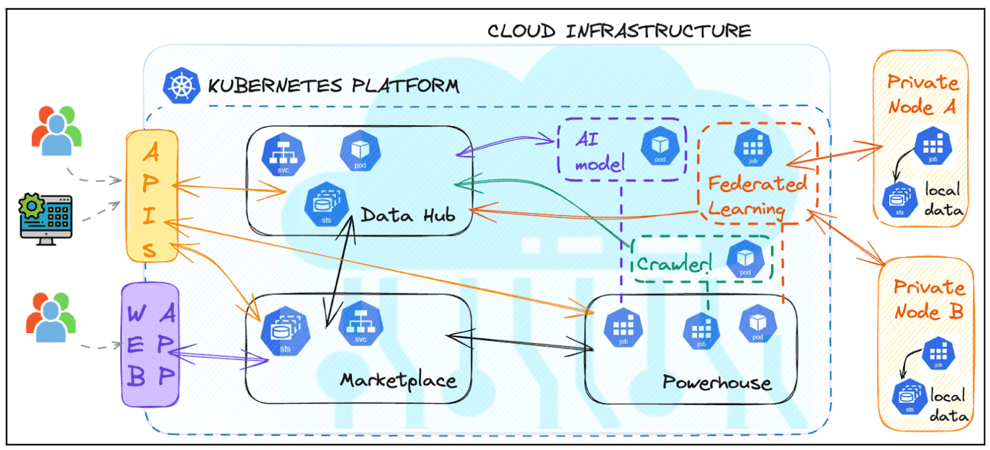
The following picture presents EFRA Core components designed as a collection of microservices, managed by Kubernetes and instantiated over a cloud infrastructure. Each component is isolated in a distinct namespace (Data Hub, Powerhouse, Marketplace) and exposes services to the other components in the cluster (e.g., access a dataset, run an AI model, start a Federated Learning training), while a layer of authenticated APIs expose platform functionalities to both users and external script/applications (e.g., store a dataset, upload and validate an AI model, schedule its execution, ..).
While Google Cloud’s web console offers a user-friendly interface for managing infrastructure, it can give a false sense of simplicity. At first glance, deploying services, configuring resources, and monitoring workloads seem straightforward. However, as the system grows, so does the risk of introducing hidden complexity. One of the main challenges is the lack of traceability: it becomes difficult to reconstruct the history of changes, identify who made specific modifications, or understand why certain configurations were applied. Moreover, knowledge and skills acquired through manual operations in the Google Cloud console are often not transferable to other cloud providers, leading to vendor lock-in and reduced portability.
This is where Terraform proves invaluable.
What is Terraform?
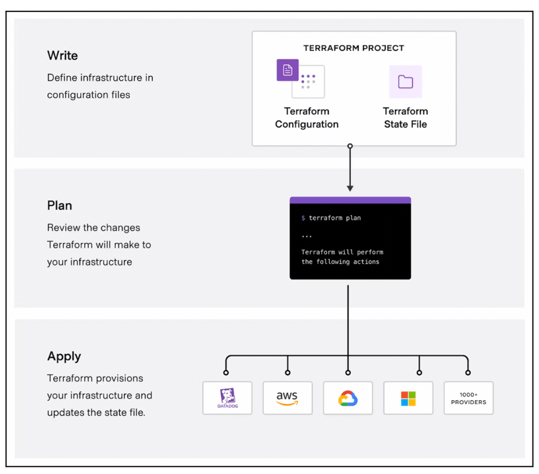
Terraform is an Infrastructure as Code (IaC) tool developed by HashiCorp. It allows you to define and provision cloud infrastructure using a declarative configuration language.
Why manage infrastructure with Terraform?
1. Version control: infrastructure changes are tracked like code.
2. Reproducibility: identical environments can be spun up reliably.
3. Modularity: infrastructure can be broken into reusable modules.
4. Plan and preview: you can see what will change before applying it.
5. Multi-cloud support: one tool, one language, many providers.
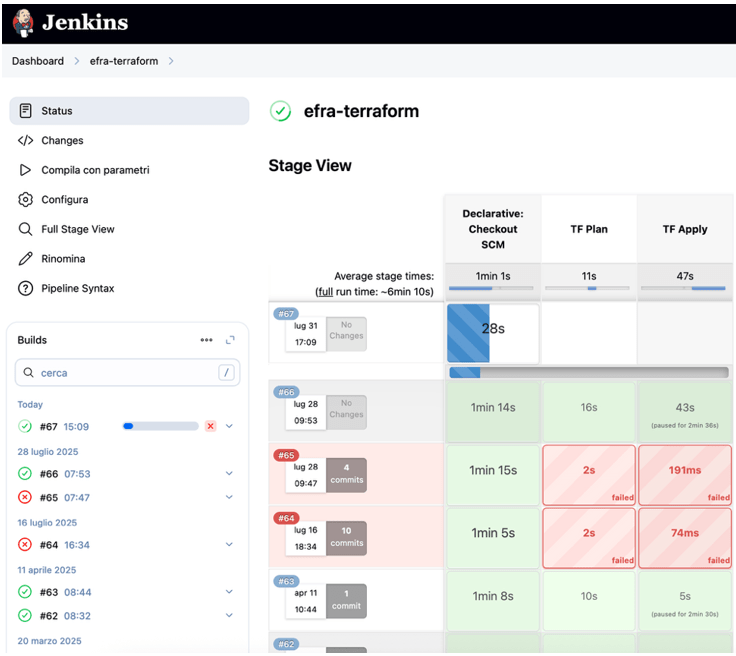
To ensure secure and auditable infrastructure management, we set up a dedicated Jenkins instance that acts as the sole executor of Terraform plans and applies. Only authorized users are allowed to trigger infrastructure changes through Jenkins, while individual users are not granted direct privileges on Google Cloud. Instead, users interact solely with the Terraform codebase: they can modify the configuration locally and push changes to the Git repository.
Once changes are pushed, Jenkins — impersonating a privileged service account — retrieves the updated code, generates a Terraform plan, and presents the proposed changes. The user can then review the plan and explicitly approve or reject the execution. This workflow ensures that no infrastructure modifications can be made directly from a personal machine, reducing the risk of accidental or unauthorized changes. Additionally, the full history of Terraform executions, including plans and applies, is preserved within Jenkins, providing a clear audit trail for every infrastructure intervention.

What is Helm?
Helm is the package manager for Kubernetes. It lets you define, install, and upgrade complex Kubernetes applications using reusable “charts”.
In our setup, we chose to integrate Helm into our Terraform modules, allowing us to manage both infrastructure and application layers declaratively and consistently. This approach gave us:
- Abstraction from underlying tech: We can switch cloud providers or Kubernetes distributions with minimal changes.
- Centralized management: Everything is orchestrated through Terraform, from clusters to app deployments.
Other benefits of Helm:
1. Powerful templating: Parameterize your YAML manifests for flexibility.
2. Release management: Track, upgrade, and roll back deployments easily.
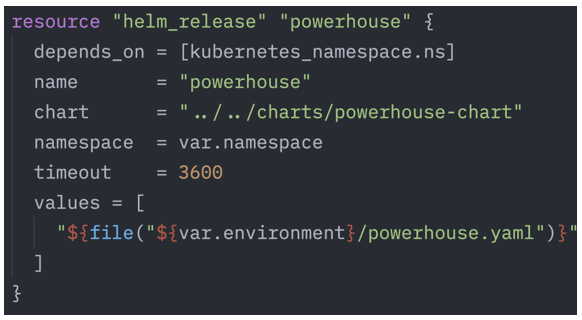
In our architecture, each application is defined by its own dedicated Helm chart. These charts go beyond simply describing how to instantiate a container and configure its runtime parameters (i.e., the deployment). They also encapsulate the application’s dependencies — such as databases (via StatefulSets) and networking configurations (e.g., Services and Ingresses) to ensure proper accessibility both within and outside the Kubernetes cluster.
Once a chart is defined, it becomes an atomic, reusable component that can be installed via Terraform on Kubernetes. From Terraform’s perspective, it is sufficient to specify which chart to use and which values to inject into the template. For example, the Powerhouse component is deployed by referencing its Helm chart and providing the necessary configuration values. This approach allows us to manage infrastructure and application layers in a unified, declarative, and reproducible way.
Final thoughts
Deploying the EFRA platform has been a deeply instructive and rewarding experience. By embracing cloud-native principles and leveraging tools like Kubernetes, Terraform, Helm, and Jenkins, we’ve built a robust and scalable infrastructure capable of supporting complex AI-driven workflows in the domain of food safety. The architectural choices we made have proven effective not only in meeting technical requirements, but also in simplifying long-term maintenance and operational overhead.
We are particularly satisfied with the balance we achieved between flexibility and control. The declarative nature of our setup allows us to evolve the platform confidently, knowing that every change is traceable, reproducible, and auditable. This foundation empowers us to focus on innovation and research, rather than firefighting infrastructure issues — an outcome that any developer or DevOps engineer can appreciate.
Article originally posted on Medium.



